 Урок 2.8. Понятие Deep Learning и Machine Learning, в чем отличие
Урок 2.8. Понятие Deep Learning и Machine Learning, в чем отличие


Крупные языковые модели (LLM) становятся все более умными, однако их разработка требует значительных технических знаний и вычислительных мощностей. Только несколько компаний в мире, такие как OpenAI, Google, Anthropic и Meta, а также "Яндекс" в России, обладают необходимыми ресурсами для создания своих собственных LLM.

Мультимодальность становится все более важным преимуществом в области искусственного интеллекта. Большинство инструментов ИИ работают только с определенными форматами контента, такими как текст, изображения или аудио. Мультимодальные модели, такие как GPT-4 и Gemini, способны анализировать и сопоставлять различные типы информации, что открывает новые возможности, включая создание контента и взаимодействие с умными виртуальными помощниками.

Развитие кастомных LLM-моделей также наблюдается в последнее время. Эти модели разрабатываются для конкретных отраслей и задач и становятся все более популярными. Примеры таких моделей включают Harvey, который специализируется на юридических вопросах, Character AI и Ava, которые создают цифровых компаньонов, и Clinical Camel, модель медицинского языка. Кастомные модели эффективны, экономичны и могут быть адаптированы для конкретных задач. Платформы, такие как Hugging Face, Cohere и другие, делают создание и использование специализированных моделей доступным и простым.
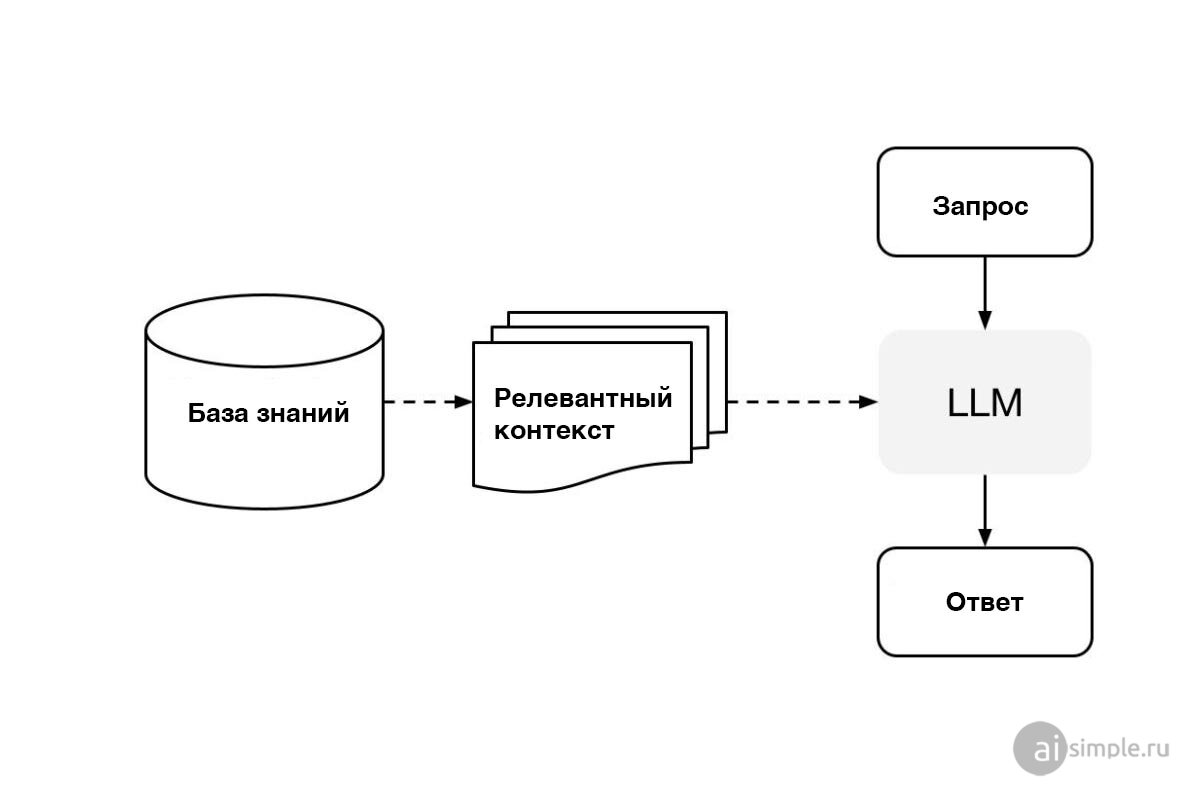
RAG (поисково-дополненная генерация) — это один из самых актуальных инструментов генеративного ИИ. Он позволяет моделям ИИ учитывать информацию, которой они изначально не обучались. В отличие от тонкой настройки, которая изменяет модель, RAG позволяет моделям временно использовать внешние данные для ответов, а затем забывать об этом.
RAG уменьшает потребность в постоянном переобучении моделей с учетом новых данных, сокращая вычислительные затраты. А использование внешних баз знаний повышает точность ответов и позволяет пользователям проверять источники ответов ИИ. RAG обеспечивает и более эффективное взаимодействие, чем традиционные чат-боты со сценариями, которые ограничены и не могут быстро адаптироваться к новым запросам без обновления вручную. Это позволяет LLM предоставлять персонализированные ответы, сверяясь с последними документами. Вдобавок RAG сводит к минимуму риск утечки конфиденциальных данных или "галлюцинаций", ведь модель использует информацию, поддающуюся проверке. Например, IBM использует RAG в своих чат-ботах для внутреннего обслуживания клиентов, обеспечивая точные, индивидуальные ответы за счет информации непосредственно из внутренних документов и политик компании. Несмотря на трудности, связанные со сложными вопросами, RAG остается важным средством снижения постоянной потребности в обновлениях LLM для компаний, располагающих большими базами данных.

Без четких регулирующих правил и инструкций по эксплуатации, искусственный интеллект может привести к усугубляющим негативным последствиям, которые перевешивают плюсы от его использования. Недавний отчет Risconnect показывает, что большинство компаний (93%) предвидят значительные угрозы, связанные с генеративным искусственным интеллектом, что свидетельствует о всеобщем осознании этой преобразующей, но потенциально небезопасной технологии. Тем не менее только 9% компаний заявляют, что готовы управлять рисками, связанными с использованием ИИ.
Основными проблемы, с которыми сталкиваются компании, являются:
Разрыв между интересами в области ИИ и стратегической готовностью указывает на то, что технология развивается настолько быстро, что компании не знают, с чего начать. С учетом перечисленных рисков, наиболее целесообразным для компаний является последовательный подход. Он должен начинаться с анализа юзкейсов (use-case), прототипирования и определения данных, которые будут использоваться в этих кейсах. Последний фактор определяет риски, связанные с оперированием конфиденциальной или чувствительной информацией в LLM. Выбрав кейс и собрав данные, можно запускать пилот, в процессе проведения которого станет понятно, какое решение подходит для достижения целей - облачное или on-prem (непосредственно на месте).
Подготовлено с использованием материалов РБК Pro.